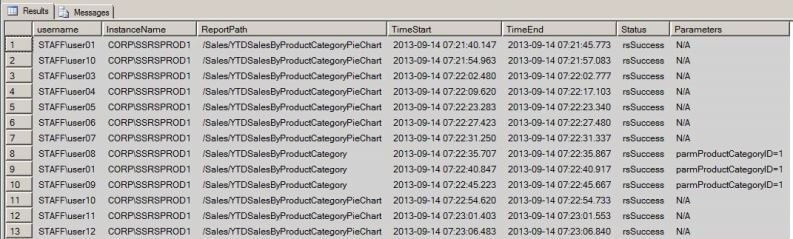
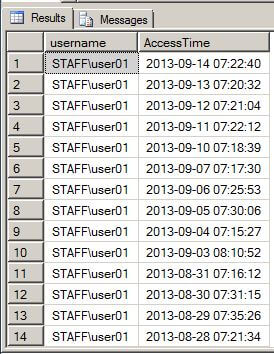
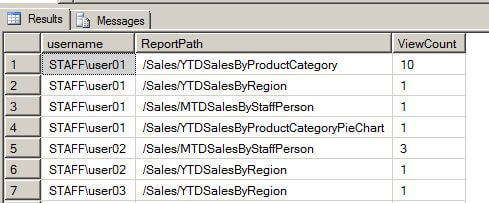
Linked Server Setup with Oracle in SQL Server:
Suppose you want to access data from oracle or other database products using T-SQL via SQL server database Engine then you need to configure Linked Server.
Here I show an example to setup linked server with oracle.
First install oracle client on machine where you want to configure linked server.
Go to [Oracle Client Installation Directory]\product\11.2.0\]dbhome_1\NETWORK\ADMIN
Open tnsnames.ora file.(It is Network configuration file for oracle)
Add TNS setting in this file as Example here
PROD =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS =
(PROTOCOL = TCP)
(HOST = 192.168.10.10)
(PORT = 1521)
)
)
(CONNECT_DATA =
(SERVICE_NAME = PROD)
)
)
Test oracle connection:
Open cmd
Enter SQLPLUS
Enter USERNAME: username@PROD
Enter PASSWORD: password
Type any select query to confirm connection.
Now come on SQL Server.
In object explorer, Expand Server Object tree Node and see linked server
Right click on linked server and select New Linked Server and Enter required information


Select Security option and enter credentials

Click Ok.
If all things are right linked server configured now.
Now Test your linked server.
Run query as
SELECT a.*
FROM OPENQUERY(linkedservername,'SELECT *from oracledatabasename.table_or_view') a;
Basic Syntax of OPENQUERY
OPENQUERY ( linked_server ,'query' )
Using OpenQuery you can INSERT,DELETE , UPDATE,DELETE.
Example Select Query:
SELECT a.*
FROM OPENQUERY(PRODNEW,'SELECT *from Apps.customer_details') a;
Example INSERT Query:
INSERT OPENQUERY (PRODNEW, ‘SELECT ID,name FROM Apps.customer_details’)
VALUES ('C121’,’Uma Shankar');
Example UPDATE Query:
UPDATE OPENQUERY (PRODNEW, 'SELECT name FROM Apps.customer_details WHERE id = ''C121''')
SET name = 'Uma Shankar Patel';
Example DELETE Query:
DELETE OPENQUERY (PRODNEW, 'SELECT ID FROM Apps.customer_details WHERE ID = ''C121''');
This query fetch data from oracle via SQL server database engine.
It is the little about linked server.I have learned this when my client require to develop a web site that fetch data from sql server but customer data of client comes from oracle.
- Insert data from Oracle to SQL Server over linked server
INSERT INTO sqldatabasename.dbo.tablename
(
- Insert data from SQL server to Oracle over linked server
INSERT INTO OPENQUERY(linkedservername,'select
SELECT
- Delete data from Oracle over linked server
DELETE OPENQUERY (linkedserver, 'Select *from oracetablename');
In the same way you can create linked server with oracle,mysql and other rdbms and can use above sample query as required.
INSERT INTO OPENQUERY(linkedservername,'select
col1,
col2,
col3
from oracletablename')
SELECT
col1,
col2,
col3
FROM sqldatabase.dbo.tablename;
- Delete data from Oracle over linked server
DELETE OPENQUERY (linkedserver, 'Select *from oracetablename');
In the same way you can create linked server with oracle,mysql and other rdbms and can use above sample query as required.
Update oracle table from SQL Server
-
UPDATE u
- UPDATE uSET u.oraclefieldname = ‘value’fromopenquery(likedservername,'select *from oracletable') as uwhere u.hdr_id = @rid